Introduction:
A covering index is a form of a non-clustered composite index, which includes all of the columns referenced in the SELECT, JOIN, and WHERE clauses of a query. Because of this, the index contains the data the query is looking for and SQL Server does not have to look up the actual data in the table, reducing logical and/or physical I/O, and boosting performance.
Impact:
Covering indexes are used to boost query performance because the index includes all the columns in the query. Non-clustered indexes include a row with an index key value for every row in a table. In addition, SQL Server can use these entries in the index’s leaf level to perform aggregate calculations. This means that SQL Server does not have to go to the actual table to perform the aggregate calculations, which can boost performance.
While covering indexes boost retrieval performance, they can slow down INSERT, DELETE, and UPDATE queries. This is because extra work is required for these procedures to maintain a covering index. This is generally not a problem, unless your database is subject to a very high level of INSERTs, DELETEs, and UPDATEs. You may have to experiment with covering indexes to see if they help more than they hurt performance before you implement them in your production systems.
Example:
To cover the query, each column must be defined in the index. The following statement creates an index with included columns to cover the query.
CREATE NONCLUSTERED INDEX NCI_Covering
ON DATABASELOG ([PostTime],[DatabaseUser],[Event],[Schema])
Performance:
Case 1: Without Any Indexes
Where there are no indexes on the table, there is no other way of returning data except to perform a table scan. Your query will run through the entire table, row by row, to fetch the record(s) that matches your query conditions.
 Case 2: With Covering Index
Case 2: With Covering Index
Our next scenario includes a covering index. As a covering index includes all the information for the query, SQL Server will retrieve the data faster and with less resource utilization. In addition, with a covering index, you won’t get as complex an Execution Plan.

A covering index is a form of a non-clustered composite index, which includes all of the columns referenced in the SELECT, JOIN, and WHERE clauses of a query. Because of this, the index contains the data the query is looking for and SQL Server does not have to look up the actual data in the table, reducing logical and/or physical I/O, and boosting performance.
Impact:
Covering indexes are used to boost query performance because the index includes all the columns in the query. Non-clustered indexes include a row with an index key value for every row in a table. In addition, SQL Server can use these entries in the index’s leaf level to perform aggregate calculations. This means that SQL Server does not have to go to the actual table to perform the aggregate calculations, which can boost performance.
While covering indexes boost retrieval performance, they can slow down INSERT, DELETE, and UPDATE queries. This is because extra work is required for these procedures to maintain a covering index. This is generally not a problem, unless your database is subject to a very high level of INSERTs, DELETEs, and UPDATEs. You may have to experiment with covering indexes to see if they help more than they hurt performance before you implement them in your production systems.
Example:
For example, assume that you want to design an index to cover the following query.
Select [PostTime],[DatabaseUser],[Event],[Schema] from DatabaseLog
To cover the query, each column must be defined in the index. The following statement creates an index with included columns to cover the query.
CREATE NONCLUSTERED INDEX NCI_Covering
ON DATABASELOG ([PostTime],[DatabaseUser],[Event],[Schema])
Performance:
Case 1: Without Any Indexes
Where there are no indexes on the table, there is no other way of returning data except to perform a table scan. Your query will run through the entire table, row by row, to fetch the record(s) that matches your query conditions.
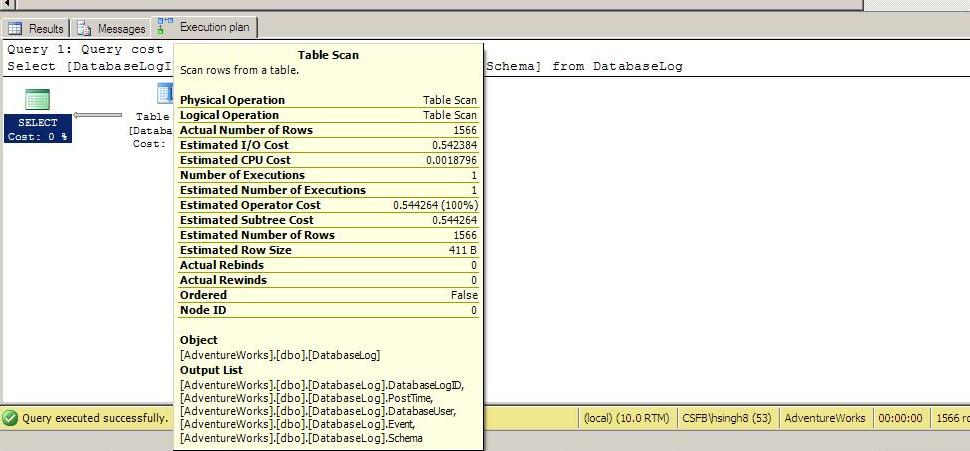
Our next scenario includes a covering index. As a covering index includes all the information for the query, SQL Server will retrieve the data faster and with less resource utilization. In addition, with a covering index, you won’t get as complex an Execution Plan.

With a covering index, the execution time of the SELECT query has been reduced. When you compare this result to not using any indexes, you can see that it has an improvement. CPU cost and I/O Cost also improved, which means that after the covering index was introduced, the query uses fewer resources for SELECT queries.
Conclusion
As the above statistics suggest, covering indexes offer both advantages and disadvantages. It is your job as the SQL Developer to determine whether the advantages outweigh the disadvantages, and whether implementing a covering index is best for your specific needs.
No comments:
Post a Comment